NVIDIA researchers introduced ProRL AGENT, a scalable infrastructure designed for reinforcement learning (RL) training of multi-turn LLM agents. By adopting a ‘Rollout-as-a-Service’ philosophy, the system decouples agentic rollout orchestration from the training loop. This architectural shift addresses the inherent resource conflicts between I/O-intensive environment interactions and GPU-intensive policy updates that currently bottleneck agent development.
The Core Problem: Tight Coupling
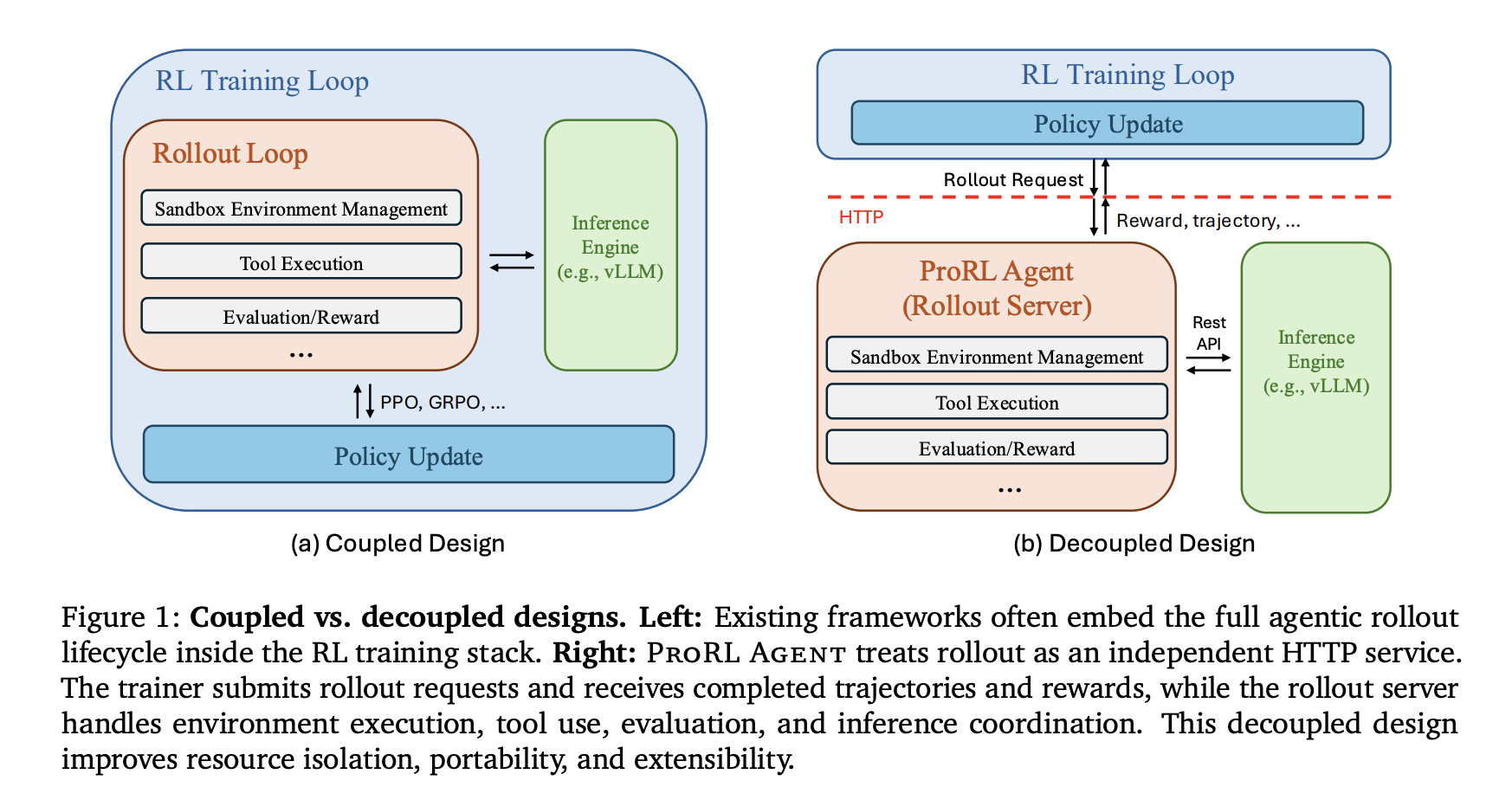
Multi-turn agent tasks involve interacting with external environments, such as code repositories or operating systems, via iterative tool use. Many existing frameworks—including SkyRL, VeRL-Tool, Agent Lightning, rLLM, and GEM—embed rollout control directly within the training process.
This tight coupling leads to two primary limitations:
- Conflicting System Requirements: Rollouts are I/O-bound, requiring sandbox creation, long-lived tool sessions, and asynchronous coordination. Training is GPU-intensive, centered on forward/backward passes and gradient synchronization. Running both in one process causes interference and reduces hardware efficiency.
- Maintenance Barriers: Embedding rollout logic in the trainer makes it difficult to migrate to different training backends or support new runtime environments without re-implementing the execution pipeline.
System Design: Rollout-as-a-Service
ProRL AGENT operates as a standalone HTTP service that manages the full rollout lifecycle. The RL trainer interacts with the server solely through an API, remaining agnostic to the underlying rollout infrastructure.

Three-Stage Asynchronous Pipeline
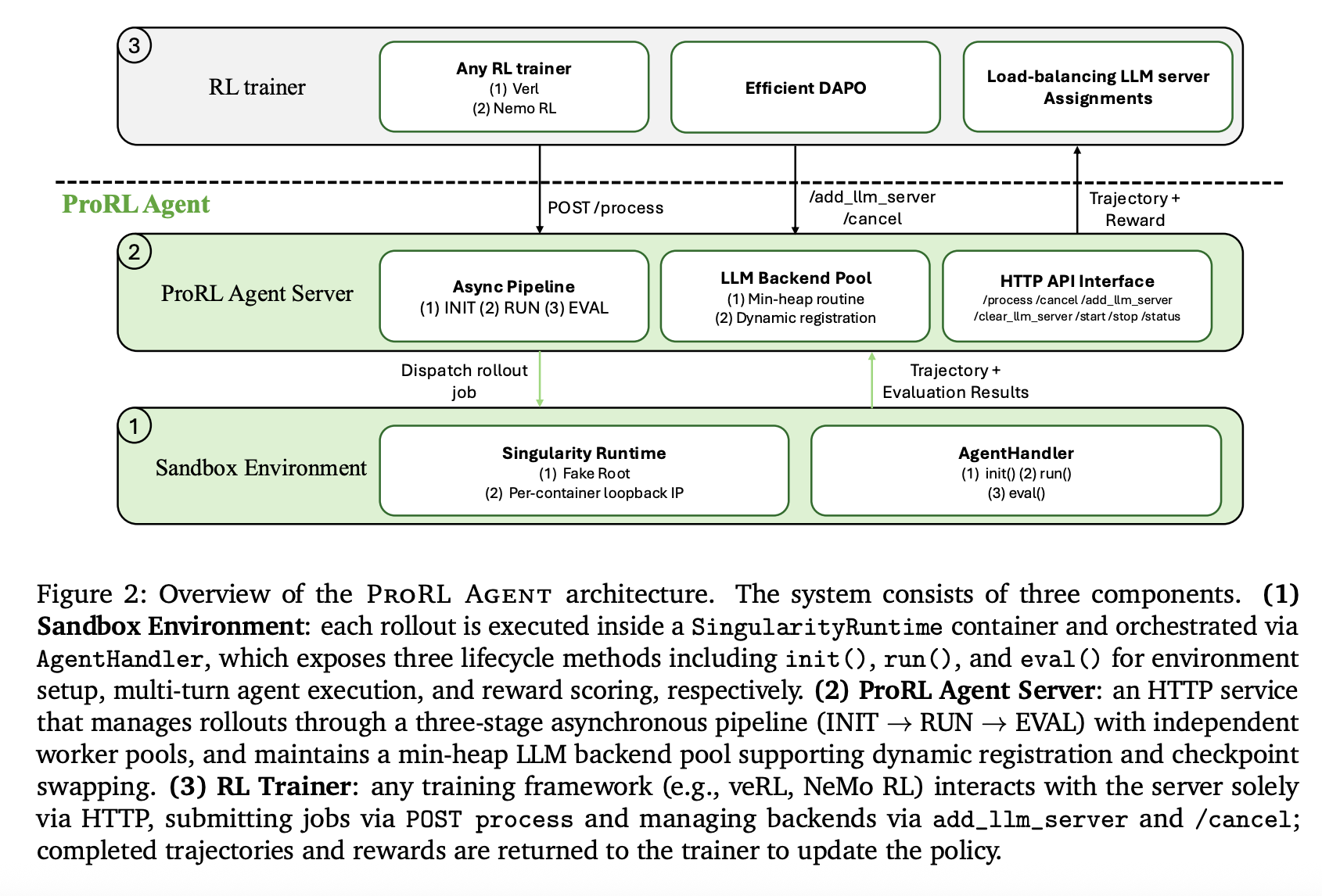
To maximize throughput, the server orchestrates rollouts through an asynchronous three-stage ‘assembly line’:
By assigning each stage to an independent worker pool, ProRL AGENT allows phases to overlap across different jobs, preventing slow evaluations (such as full test suite executions) from stalling the rollout process.
HPC-Compatible Sandboxing and Optimized Tools
ProRL AGENT utilizes Singularity for its sandbox infrastructure. Unlike Docker-based platforms, Singularity allows rootless execution, which is required for deployment on shared HPC clusters managed by Slurm.
The system includes several optimizations to reduce tool execution latency, which often dominates total rollout time:
- Efficient Bash: Replaces tmux-based terminal multiplexing with a ptyprocess-based direct pseudo-terminal, reducing shell command latency from 0.78s to 0.42s.
- Direct IPython API: Connects to persistent kernels via an in-process API instead of network gateways, removing networking overhead.
- Unix Domain Sockets (UDS): Replaces TCP loopback for communication between the agent and the execution server inside the container to shave off additional latency.
Advanced Features for Scalable RL
The infrastructure introduces mechanisms to improve training stability and hardware utilization:
Load Balancing and Prefix Cache Reuse
The server manages a pool of LLM inference backends (e.g., vLLM) using a min-heap keyed by assignment counts. When a task is assigned, all subsequent calls within that task are routed to the same backend. This strategy maximizes prefix cache reuse, reducing inference time across multiple agent turns.
Token-in/Token-out Communication
To eliminate re-tokenization drift—where the token sequence generated during rollout differs from what is used during training—ProRL AGENT uses token IDs as the canonical representation throughout the entire process. Log-probabilities and IDs are propagated unchanged from the inference backend to the trainer.
Optimized DAPO Implementation
The system supports Dynamic Sampling Policy Optimization (DAPO), which filters out ‘non-informative’ prompts that yield uniform rewards. ProRL AGENT uses an asynchronous replenishment mechanism to maintain maximum throughput, terminating redundant active jobs early once the target number of informative prompts is reached.
Experimental Results on SWE-Bench Verified
The system was validated using Qwen3 models across multiple scales. ProRL AGENT consistently improved performance compared to reproduced baselines.
Note: The reported prior result for SkyRL-Agent-14B-v0 was 21.6.
In addition to software engineering, the system demonstrated generality in STEM, Math, and Code domains, showing steady reward growth during RL training. Scalability tests confirmed that rollout throughput increases near-linearly as compute nodes are added.
Key Takeaways
- Architectural Decoupling: ProRL Agent treats the full agentic rollout lifecycle—including environment initialization, tool execution, and reward scoring—as an independent HTTP service, separating I/O-intensive tasks from GPU-intensive policy training.
- Significant Performance Gains: This infrastructure enabled the Qwen3-8B model to nearly double its performance on the SWE-Bench Verified benchmark (from 9.6% to 18.0%), while the Qwen3-14B model improved from 15.4% to 23.6%.
- System Latency Reductions: Targeted optimizations, such as replacing tmux with ptyprocess for shell execution, reduced action latency from 0.78s to 0.42s, contributing to near-linear throughput scaling across compute nodes.
- Elimination of Tokenization Drift: The framework utilizes a token-in/token-out communication pipeline, ensuring that the exact token IDs generated during rollout are passed to the trainer without the risk of lossy re-tokenization.
- HPC-Native Deployment: By using Singularity instead of Docker, ProRL Agent supports rootless execution and native Slurm integration, allowing large-scale agent training on shared high-performance computing clusters.
Check out the Paper and Repo. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.